🙂 다양한 데이터 웨어하우스 옵션
✔ 데이터의 흐름과 데이터 팀의 발전 단계

🍦 데이터 웨어하우스 (DW)
회사가 필요한 모든 데이터를 모아놓은 중앙 데이터베이스 (SQL 데이터베이스)
- 데이터의 크기에 맞게 어떤 데이터베이스를 사용할 지 선택
- AWS Redshift, 구글 클라우드의 BigQuery
- 스노우플레이크(Snowflake) - 클라우드와 상관 없음
- 오픈소스 기반의 하둡(Hive/Presto) / 스팍(Spark)
- 모두 SQL 지원
- 프로덕션용 데이터베이스와 별개의 데이터베이스여야 함.
- DW의 구축이 진정한 데이터 조직이 되는 첫 번째 스텝
🍦 ETL (Extract, Transform, Load)
다른 곳에 존재하는 데이터를 가져다가 DW에 로드하는 작업
- Extract: 외부 데이터 소스에서 데이터를 추출
- Transform: 데이터의 포맷을 원하는 형태로 변환
- Load: 변환된 데이터를 최종적으로 DW에 적재
- 데이터 파이프라인이라고 부르기도 함.
가장 많이 사용하는 Framework는 Airflow
- Airflow는 오픈소스 프로젝트로 Python 3 기반이며 Airbnb에서 시작
- AWS와 구글 클라우드에서도 지원
ETL 관련 SaaS도 출현
- 흔한 데이터 소스의 경우 FiveTran, Stitch Data와 같은 SaaS 사용.
🍦 시각화 대시보드
보통 중요한 지표를 시간의 흐름과 함께 보여주는 것이 일반적
- 지표의 경우 3A(Accessible, Actionable, Auditable)
- 중요 지표의 예: 매출액, 월간/주간 액티브 사용자 수, ...
- Looker, Tableau, Power BI, Superset
🍦 Machine Learning
(프로그래밍 없이) 배움이 가능한 알고리즘
A field of study that gives computers the ability to learn without being explicitly programmed.
- Arthur Sameul
데이터로부터 패턴을 찾아 학습
- 데이터의 품질과 크기가 중요
- 데이터로 인한 왜곡 (bias) 발생 가능 (AI 윤리)
- 내부동작 설명 가능 여부도 중요 (ML Explainability)
✔ 데이터 조직 구성원
🍦 데이터 엔지니어 (Data Engineer)
데이터 인프라 (DW와 ETL) 구축
- DW를 만들고 이를 관리. 클라우드가 추세
- AWS의 Redshift, 구글클라우드의 BigQuery, Snowflake
- 관련해서 중요한 작업 중의 하나는 ETL 코드를 작성하고 주기적으로 실행.
- ETL 스케줄러 혹은 Framework이 필요 (Airflow)
기술 지식
- SQL: 기본 SQL, Hive, Presto, SparkSQL, ...
- 언어: Python, Scala, Java
- DW: Redshift / Snowflake / BigQuery
- ETL/ELT Framework: Airflow, ...
- 클라우드: AWS, GCP, Azure
+ - 대용량 데이터 처리 플랫폼: Spark / YARN
- 컨테이너 기술: Docker / K8s
- 기타 지식: 머신러닝, A/B 테스트, 통계
- MLOps 혹은 ML Engineer가 다음 스텝
- 로드맵
🍦 데이터 분석가 (Data Analyst)
비지니스 인텔리전스를 책임짐
- 중요 지표를 정의하고 대시보드 형태로 시각화
- 대시보드: Tableau / Looker
- 오픈소스로는 Superset 사용
- 비지니스 도메인 지식
기술 지식
- SQL: 기본 SQL, Hive, Presto, SparkSQL, ...
- 대시보드
- Looker, Tableau, Power BI, Superset
- Excel, Google SpreadSheet, Python
- 데이터 모델링
- 통계 지식
- 비지니스 도메인 지식
- 좋은 지표를 정의하는 능력
딜레마
- 많은 수의 긴급한 데이터 관련 질문 처리
- 좋은 데이터 인프라가 필요
- 많은 경우 현업 팀에 소속
- 조직 구조가 매우 중요
🍦 MLOps
DevOps
- 개발자가 만든 코드를 시스템에 반영하는 프로세스 (CI/CD, deployment)
- 시스템이 제대로 동작하는지 모니터링 그리고 이슈 감지 시 escalation 프로세스 (On-call)
MLOps
- DevOps가 하는 일과 동일. 대신 서비스 코드가 아니라 ML 모델이 대상.
- 모델을 계속적으로 빌딩하고 배포하고 성능 모니터링
- ML 모델 빌딩과 프로덕션 배포 자동화 - 계속적인 모델 빌딩과 배포
- 모델 서빙 환경과 모델 성능 저하를 모니터링하고 필요 시 escalation 프로세스
기술 지식

- 데이터 엔지니어 기술
- Python / Scala / Java
- 데이터 파이프라인과 DW
- DevOps 엔지니어 기술
- CI/CD, 서비스 모니터링, ...
- 컨테이너 기술 (Docker, K8s)
- 클라우드
- 머신러닝
- 머신러닝 모델 빌딩과 배포
- ML 모델 빌딩 Framework 경험
- SageMaker, Kubeflow, MLflow
🍦 프라이버시 엔지니어
전체 시스템에서 개인정보 보호를 위한 가이드라인 / 툴 제공
- 개인정보: 개인을 식별할 수 있는 정보
개인 정보 보호 법안의 징벌 조항 강화 추세
- EU의 GDPR
- 미국의 HIPAA
- 미국 California의 CCPR
🍦 Data Discovery
데이터가 커지면 테이블과 대시보드의 수가 증가
- 데이터 분석 시 어느 테이블이나 대시보드를 봐야하는 지 혼란
-> 직접 새로운 테이블이나 대시보드 생성
-> 정보 과잉 문제로 악순환 - 주기적인 테이블과 대시보드 클린업이 필수
테이블과 대시보드 관련 검색 서비스
- 리프트에서 만든 아문센
- 링크드인에서 만든 데이터허브
- 셀렉트스타
✔ 데이터 웨어하우스와 ETL / ELT

🍦 DW 옵션 별 장단점
- 고정비용 vs. 가변비용(확장가능)
- RedShift (고정비용) / BigQuery, Snowflake (가변비용)
- 데이터 웨어하우스는 기본적으로 클라우드
- 오픈소스 기반(Presto, Hive)에도 클라우드 버전 존재
- 데이터가 커져도 문제가 없는 확장가능성(Scalable)과 적정한 비용이 중요
- 데이터가 작다면 굳이 빅데이터 기반 DB 사용할 필요가 없음
🍦 데이터 레이크
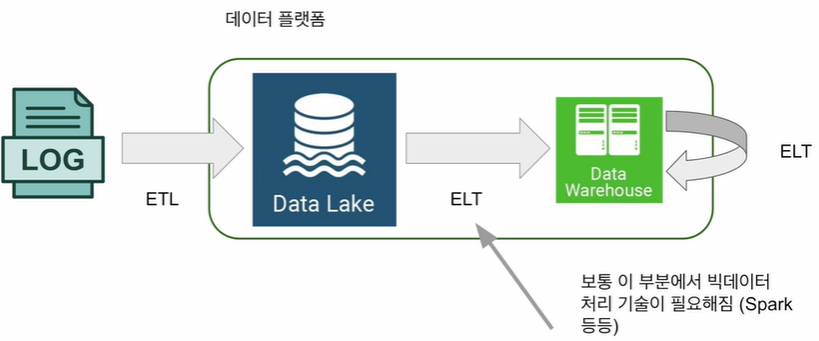
- 구조화 데이터 + 비구조화 데이터 (로그 파일)
- 보존 기한이 없는 모든 데이터를 원래 형태대로 보존하는 스토리지에 근접
- 보통은 데이터 웨어하우스보다 몇 배는 더 크고 더 경제적인 스토리지
- 보통 클라우드 스토리지
- AWS의 경우 S3
- 데이터 레이크가 있는 환경에서 ETL과 ELT
- ETL: Data Lake와 DW 바깥에서 안으로 데이터를 가져오는 것
- ELT: Data Lake와 DW 안에 있는 데이터를 처리하는 것
🍦 ETL (Extract, Transform, Load) -> ELT
ETL의 수는 회사의 성장에 따라 쉽게 100+개 이상으로 발전
- 중요한 데이터를 다루는 ETL이 실패했을 경우 이를 빨리 고쳐서 다시 실행하는 것이 중요
- 이를 적절하게 스케줄하고 관리하는 것이 중요해지며 ETL 스케줄러 혹은 프레임워크가 필요 -> Airflow
데이터 요약을 위한 ETL도 필요 = ELT
- 앞의 ETL은 다양한 데이터 소스에 있는 데이터를 읽어옴
- 주기적으로 요약 데이터를 만들어 사용하는 것이 효율적. DBT 사용
- 예) 고객 매출 요약 테이블, 제품 매출 요약 테이블, ...
🍦 ELT
- ETL: 데이터를 DW 외부에서 내부로 가져오는 프로세스
- 데이터 엔지니어 업무
- ELT: DW 내부 데이터를 조작해서 (좀 더 추상화되고 요약된) 새로운 데이터를 만드는 프로세스
- dbt가 가장 대중적: Analytics Engineering
- 데이터 분석가 업무
- 데이터 레이크 사용
🍦 다양한 데이터 소스
- 프로덕션 데이터베이스
- 이메일 마케팅 데이터
- 신용카드 매출 데이터
- Support 티켓 데이터
- Support 콜 데이터
- Sales 데이터
- 사용자 이벤트 로그
🍦 Airflow (ETL 스케쥴러)
- 오픈소스 프로젝트로 Python 3 기반.
- ETL을 DAG라 호칭.
- 3가지 컴포넌트
- 스케쥴러
- 웹 서버
- 워커
- Backfill: 특정 ETL이 실패할 경우 이에 관한 에러 메세지를 받고 재실행하는 기능
🍦 빅데이터 처리 Framework
분산 환경 기반 (1대 혹은 그 이상의 서버로 구성)
- 분산 파일 시스템과 분산 컴퓨팅 시스템이 필요
Fault Tolerance
- 소수 서버가 고장나도 동작
확장 용이성
- Scale Out
- 용량 증대를 위해 서버 추가
대표적인 시스템
- 1세대: 하둡 기반의 MapReduce, Hive/Presto
- 2세대: Spark (SQL, DataFrame, Streaming, ML, Graph) - YARN 위에서 동작하는 시스템

✔ 데이터 웨어하우스 옵션
SQL을 지원하는 빅데이터 기반 데이터베이스 (Apache Iceberg 제외)
🍦 AWS Redshift
- 2012년에 시작된 AWS 기반의 DW로 PB 스케일 데이터 분산 처리 가능
- Postgresql과 호환되는 SQL로 처리 가능
- Python UDF (User Defined Function)의 작성을 통해 기능 확장 가능
- 처음에는 고정비용 모델로 시작했으나 가변비용 모델도 지원 (Redshift Serverless)
- 온디맨드 가격 이외에도 예약 가격 옵션 지원
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷 지원
- AWS 내의 다른 서비스들과 연동 용이
- S3, DynamoDB, SageMaker(ML 모델 실행) 등
- Redshift의 기능 확장을 위해 Redshift Spectrum, AWS Athena 등의 서비스와 같이 사용 가능
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 이외에도 API를 통한 관리/제어 가능
🍦 Snowflake
- 2014년 클라우드 기반 DW로 시작 (2020년 상장)
- a.k.a. 데이터 클라우드
- 데이터 판매를 통한 매출을 가능하게 해주는 Data Sharing/Marketplace 제공
- ETL과 다양한 데이터 통합 기능 제공
- SQL 기반으로 빅데이터 저장, 처리, 분석 가능
- 비구조화된 데이터 처리와 머신러닝 기능 제공
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷 지원
- S3, GC 클라우드 스토리지, Azure Blog Storage 지원
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 이외에도 API를 통한 관리/제어 가능
🍦 Google Cloud BigQuery
- 2010년에 시작된 구글 클라우드의 DW 서비스
- BigQuery SQL 로 데이터 처리 가능 (Nested fields, repeated fields 지원)
- 가변 비용과 고정 비용 옵션 지원
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷 지원
- 구글 클라우드 내의 다른 서비스들과 연동 용이
- 클라우드 스토리지, 데이터플로우, AutoML 등
- 배치 데이터 중심이지만 실시간 데이터 처리 지원
- 웹 콘솔 이외에도 API를 통한 관리/제어 가능
🍦 Apache Hive
- Facebook이 2008년에 시작한 아파치 오픈소스 프로젝트
- 하둡 기반으로 동작
- HiveQL이라 부르는 SQL 지원
- MapReduce 와 Apache Tez를 실행 엔진으로 동작하는 두 가지 버전
- 다른 하둡 기반 오픈소스와 연동 용이 (Spark, HBase 등)
- Java나 Python으로 UDF 작성 가능
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷 지원
- 배치 빅데이터 프로세싱 시스템
- 데이터 파티셔닝과 버킷팅과 같은 최적화 작업 지원
- 빠른 처리속도 보다 처리할 수 있는 데이터 양의 크기에 최적화
- 웹 UI와 CLI 두 가지 지원
Spark에 밀리는 분위기
🍦 Apache Presto
- Facebook이 2013년에 시작한 아파치 오픈소스 프로젝트
- 다양한 데이터소스에 존재하는 데이터를 대상으로 SQL 실행 가능
- HDFS (Hadoop Distributed File System), S3, Cassandra, MySQL 등
- PrestoSQL 지원
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷 지원
- 배치 빅데이터 프로세싱 시스템
- Hive와 다르게 빠른 응답 속도에 최적화
- 웹 UI와 CLI 두 가지 지원
- AWS Athena가 Presto 기반
🍦 Apache Iceberg
- Netflix가 2018년에 시작한 아파치 오픈소스 프로젝트로 DW 기술이 아님
- 대용량 SCD (Slowly-Changing Datasets) 데이터를 다룰 수 있는 테이블 포맷
- HDFS, S3, Azure Blob Storage 등의 클라우드 스토리지 지원
- ACID 트랜잭션
- 스키마 진화 지원을 통한 컬럼 제거와 추가 가능 (without 테이블 재작성)
- Java와 Python API 지원
- Spark, Flink, Hive, Hudi 등 다른 Apache 시스템과 연동 가능
🍦 Apache Spark
- UC 버클리 AMPLab이 2013년에 시작한 아파치 오픈소스 프로젝트
- 빅데이터 처리 관련 종합선물세트
- 배치처리(API/SQL), 실시간처리, 그래프처리, ML 기능 제공
- 다양한 분산처리 시스템 지원
- Hadoop(YARN), AWS EMR, Google Cloud Dataproc, Mesos, K8s 등
- 다양한 파일시스템과 연동 가능
- HDFS, S3, Cassandra, HBase 등
- CSV, JSON, Avro, Parquet 등과 같은 다양한 데이터 포맷 지원
- 다양한 언어 지원: Java, Python, Scala, R
✔ 실리콘밸리 회사들의 데이터 스택 트렌드
🍦 데이터 플랫폼의 발전단계
- 초기 단계: DW + ETL
- 발전 단계: 데이터 양 증가
- Spark와 같은 빅데이터 처리시스템 도입
- Data Lake 도입: 로그 데이터와 같은 대용량 비구조화 데이터 대상

- 성숙 단계: 데이터 활용 증대
- 현업단의 데이터 활용 가속화
- ELT 단이 더 중요해지면서 dbt 등의 analytics engineering 도입
- Data Lake to Data Lake / Data Lake to Data Warehouse / Data Warehouse to Data Warehouse
- MLOps 등 머신러닝 관련 효율성 증대 노력

🍦 실리콘밸리 회사
| 회사명 | 클라우드 | Big Data 시스템 | 대시보드 | Data Pipeline Framework |
| Apple | Hybrid (on-prem) | Spark + Iceberg | 자체 제작 | Airfolw + K8s |
| Affirm | AWS | Spark + Snowflake | Looker, Snowsight | Airflow + dbt |
| AWS | Spark (Hive -> Spark2, Spark2 -> Spark3) |
Looker, Tableau, ReDash | Airflow + K8s | |
| Zillow | AWS | Spark + Iceberg | Tableau, Mode | Airflow |
| PepsiCo | AWS -> Azure | Spark (Databricks), Snowflake | Power BI, Tableau | Airflow + dbt |
| Confluent | Google Cloud | BigQuery | Tableau | Airflow + Stitch |
| Udemy | AWS | Spark (Databricks) / Hive / Redshift | Looker, Mode | Airflow + dbt |
| Uber | On-prem -> GCP, Oracle |
Hive / Presto / Spark | 자체제작 -> Tableau, Google Studio |
Airflow (forked version) |
| Airbnb | AWS | Hive / Presto | Superset | Airflow |
'데이터엔지니어링' 카테고리의 다른 글
| [7주차] 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드 (3) (0) | 2024.05.07 |
|---|---|
| [7주차] 데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드 (2) (0) | 2024.05.06 |
| [6주차] AWS 클라우드(4) (1) | 2024.05.04 |
| [6주차] AWS 클라우드(3) (1) | 2024.05.03 |
| [6주차] AWS 클라우드(2) (0) | 2024.05.02 |